O contexto
Quando se quer usar Analytics e IA no agronegócio, na indústria de alimentos, energia e meio ambiente, é preciso entender o contexto destes setores, antes de se questionar sobre qual algoritmo usar.
Estão em áreas remotas, expostas ao clima, são ou dependem fundamentalmente de recursos naturais. Possuem longos ciclos de produção e portanto são afetados por sazonalidades. Requerem infraestrutura de logística e comunicação próprias. Seus processos estão ligados a variáveis muito distribuídas no espaço, entre recursos tecnológicos e pessoas. Além de possuírem regulações governamentais e de mercado.
Qual pergunta é preciso responder?
Depois de considerar o contexto, que problema é preciso responder? Por que essa resposta é importante?
É importante escolher perguntas objetivas e cujas respostas claramente: Otimizem processos (menor tempo, menor custo, maior receita).
Seja com automação (menor interação entre pessoas e sistemas), redução de complexidade e etapas desnecessárias, mitigação de riscos (através da predição de eventos) e recomendação sobre ações baseadas em predições.
Para escolher a pergunta que se quer responder, é útil testar opções como:
- É possível automatizar esse processo?
- É possível prever esse evento?
- É possível recomendar a melhor decisão?
- É possível evitar essa atividade?
Entenda o ROI
Quando se tem uma pergunta clara, é possível saber duas coisas importantes, primeiro o benefício que a resposta trará, ou seja, o valor entregue. E segundo, quais dados levam à resposta.
Se o valor entregue pela resposta, paga o custo do acesso e processamento dos dados, o uso de Analytics e IA começa a parar de pé.
Os dados mostram o caminho
Usar Analytics e IA, basicamente significa usar tecnologia (algoritmos) para compreensão e resposta, e são os dados que levam à compreensão através de suas diferentes peculiaridades e atributos, ao longo de diferentes pontos de vista, seja no tempo ou espaço.

E também através dos tipos de dados que se possui, existem técnicas específicas para levar a compreensão. Existem duas classificações distintas de tipos de dados, Contínuos e Categóricos:
Dados contínuos
São dados que podem assumir valores em uma escala infinita ou infinitamente próximos. Por exemplo, a idade, o peso, a altura, a temperatura, etc. Esses dados são geralmente numéricos e podem ser medidos ou quantificados. Algoritmos de aprendizado de máquina como regressão linear, árvores de decisão, entre outros, são usados para analisar esses dados.
Dados categóricos
São dados que podem ser classificados em categorias ou grupos distintos. Por exemplo, gênero, cor dos olhos, tipo de carro, etc. Esses dados são geralmente descritivos e não podem ser medidos ou quantificados. Algoritmos de aprendizado de máquina como classificação, árvores de decisão, entre outros, são usados para analisar esses dados.
Como a máquina compreende/aprende?
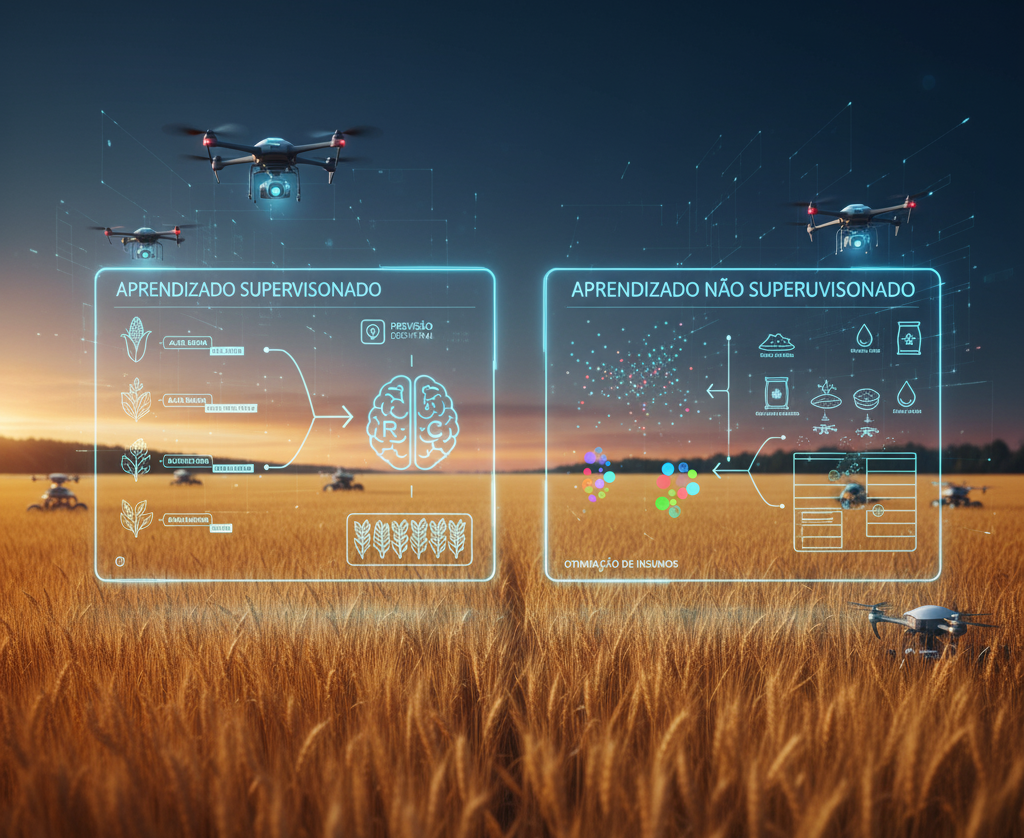
Através da classificação de dados é possível aplicar algoritmos que compreendem as nuances e variações dos dados (features) entre as diferentes características ao longo das observações. Existem dois tipos de compreensão ou aprendizado de máquina (Machine Learning), os supervisionados e os sem supervisão.
Aprendizado de máquina supervisionado
É a técnica de aprendizado de máquina onde o algoritmo aprende com base em exemplos fornecidos pelo usuário, que incluem as entradas e as saídas desejadas, que chamamos de rótulos ou labeling. O objetivo é treinar o modelo de tal forma que ele possa prever corretamente a saída dado um conjunto de entradas novas. Exemplos incluem classificação de imagens, previsão de séries temporais, etc.
Aprendizado de máquina não supervisionado
É a técnica de aprendizado de máquina onde o algoritmo aprende sem um rótulo ou saída desejada específica. O objetivo é encontrar padrões ou estruturas escondidas nos dados, sem que o usuário precise especificar o que procurar. Exemplos incluem clusterização, redução de dimensionalidade, detecção de anomalias, etc.
Amostra de algoritmos
Através do conhecimento dos tipos/classes de dados e também os tipos de aprendizado de máquina é possível entender as possibilidades gerais de algoritmos, na seguinte matriz:
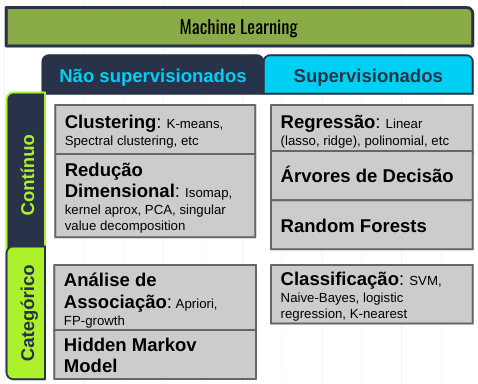
Exemplos de Machine Learning supervisionado com dados categóricos
Classificação de Spam. Um exemplo prático de uso de aprendizado supervisionado com dados categóricos seria a classificação de spam. Suponha que você tenha uma base de dados com mensagens de email, marcadas como spam ou não spam. Neste caso, você pode usar algoritmos de classificação, como a árvore de decisão, para treinar um modelo que classifique novas mensagens de email como spam ou não spam com base nas características das mensagens, como palavras-chave, remetente, etc.
Exemplo de Machine Learning supervisionado com dados contínuos
Previsão de Preços de Ações. Um exemplo prático de uso de aprendizado supervisionado com dados contínuos seria a previsão de preços de ações. Suponha que você tenha uma base de dados com informações financeiras sobre uma empresa, como lucro, receita, gastos, etc. Neste caso, você pode usar algoritmos de regressão, como a regressão linear, para treinar um modelo que preveja o preço das ações da empresa baseado nas informações financeiras.
Exemplo de Machine Learning não supervisionado com dados categóricos
Clusterização. Um exemplo prático de uso de aprendizado não supervisionado com dados categóricos seria a clusterização. Suponha que você tenha uma base de dados com informações sobre clientes, como gênero, idade, localização e comportamento de compra. Neste caso, você pode usar técnicas de clusterização, como o K-Means, para agrupar clientes semelhantes em diferentes grupos ou clusters. Isso pode ser útil para entender as características comuns dos clientes em cada grupo e para personalizar suas campanhas de marketing.
Exemplo de Machine Learning não supervisionado com dados contínuos
Redução de Dimensionalidade. Um exemplo prático de uso de aprendizado não supervisionado com dados contínuos seria a redução de dimensionalidade. Suponha que você tenha uma base de dados com milhares de características e queira representá-las de forma mais compacta para visualização ou para melhorar o desempenho de algoritmos de aprendizado de máquina. Neste caso, você pode usar técnicas de redução de dimensionalidade como o PCA (Análise de Componentes Principais) para encontrar uma representação menor dos dados que mantém a maior parte da informação.
Mas e o deep learning?
Na agricultura, indústria de alimentos, energia e meio ambiente, o deep learning pode ser útil para lidar com dados complexos, como imagens de drone e de satélite, dados espaciais e climáticos. Por exemplo, é possível usar o deep learning para classificar imagens de satélite e de drone e identificar características importantes, como áreas de cultivo, tipos de culturas, níveis de produtividade, níveis de poluição, entre outros. O deep learning também pode ser usado para prever a produção agrícola e identificar tendências climáticas.
Na indústria de alimentos, o deep learning pode ser usado para analisar imagens de alimentos e identificar características importantes, como a qualidade e a maturidade dos alimentos, além de classificar produtos e identificar falhas de qualidade.
Na indústria de energia, o deep learning pode ser usado para analisar imagens de satélite e de drone e identificar áreas de recursos energéticos, como campos de petróleo e gás, turbinas eólicas e painéis solares. O deep learning também pode ser usado para prever a demanda de energia e otimizar a distribuição de energia.
No meio ambiente, o deep learning pode ser usado para analisar dados climáticos e prever tendências, como eventos extremos e mudanças climáticas. O deep learning também pode ser usado para analisar imagens de satélite e de drone e identificar áreas de risco ambiental, como áreas de desmatamento, queimadas e poluição.
Conclusão
Primeiro, é preciso entender o setor, a pergunta que é necessário responder, o ROI que essa resposta traz, as características e nuances dos dados, quais observações de dados existem, sejam temporais ou espaciais, qual é a classificação de dados, categóricos ou contínuos. Tudo isso é fundamental para escolher os algoritmos.
Assim, é possível caminhar para a segunda parte, é necessário uma supervisão para rotular situações e então prevê-las? Ou seja, será um machine learning supervisionado ou não supervisionado?
Mas talvez os dados sejam complexos demais e nesse caso a abordagem de deep learning seja indicada. Mas no fim do dia será necessário olhar para a qualidade dos dados, e testar diversos modelos de algoritmos até a escolha final.
Nós queremos te ajudar nisso, traga suas demandas de Analytics e IA para a SciCrop!